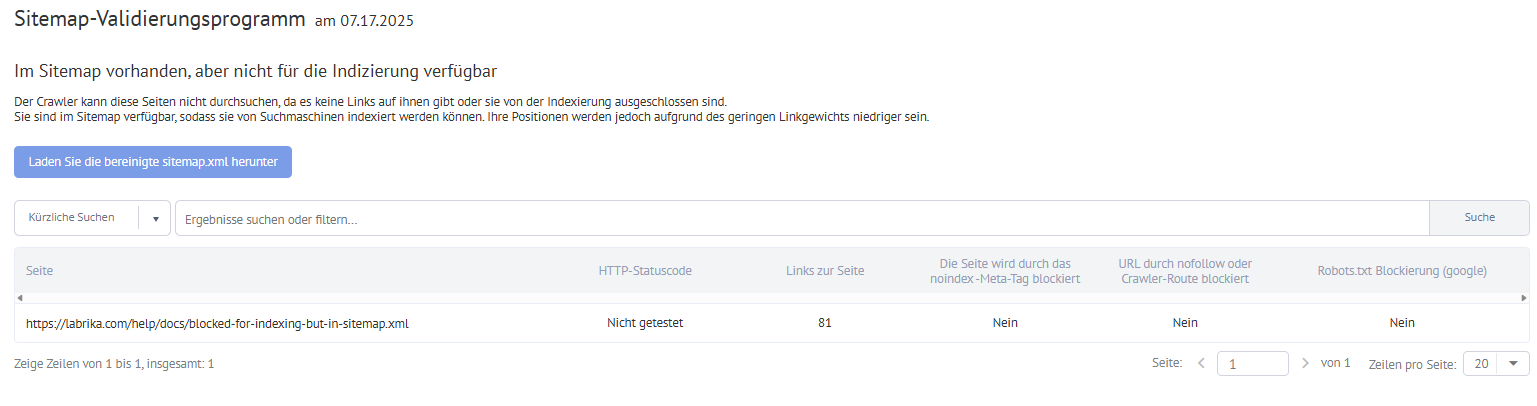
In Sitemap, aber nicht für die Indexierung verfügbar
Eine Sitemap.xml Datei ist im Wesentlichen eine Karte Ihrer Website, die speziell für eine einfache Navigation und Indexierung Ihrer Seite durch Suchmaschinen erstellt wurde. Sie befindet sich im öffentlichen public_html Ordner (oder im Stammverzeichnis der Website) und enthält wichtige Anweisungen für Suchmaschinen-Crawler, die angeben, welche Seiten besucht werden sollen, in welcher Reihenfolge und wie oft.
Dies beschleunigt den Indexierungsprozess wichtiger Seiten erheblich und ermöglicht es den Such-Crawlern, ihre Crawling-Zeit auf Seiten von hoher Bedeutung für Sie und Ihre Nutzer zu konzentrieren.
Die Erstellung einer Sitemap.xml ist nicht immer notwendig, wird jedoch immer empfohlen, insbesondere für große Websites mit Tausenden von Seiten. Mit größeren Websites entsteht die Notwendigkeit, sicherzustellen, dass Suchmaschinen-Crawler ihre Zeit auf wertvolle Seiten mit tiefen Inhalten und kommerzieller Absicht verbringen und nicht auf Neben-Seiten, die nur wenig Wert bieten.
Als Faustregel gilt, dass Software und CMS, die automatisch eine Sitemap.xml-Datei generieren, in der Regel alle verfügbaren Seiten zur Indexierung einbeziehen. Ein typischer Website-Besitzer ist sich dessen wahrscheinlich nicht bewusst, und während er möglicherweise für bestimmte Seiten „noindex“ festgelegt hat, werden diese Seiten wahrscheinlich in den automatisch generierten Sitemaps eingeschlossen, was wertvolle Crawling-Budgets verschwendet!
Es wird dringend empfohlen, Plugins, benutzerdefinierte Software oder Sitemap-Generatoren zu verwenden, um spezifische URLs zu konfigurieren, die in Ihrer Sitemap angezeigt werden sollen, bestimmte URLs zu vermeiden, in welcher Reihenfolge URLs gecrawlt werden sollen und wie oft.
Fehler in der Sitemap, die von Labrika gefunden wurden
Achtung! Der Bericht über Sitemap-Fehler ist nur zugänglich, wenn ausreichende Berechtigungen zum Scannen der gesamten Website korrekt konfiguriert sind. Andernfalls kann Labrika nur Seiten anzeigen, die speziell in der Sitemap.xml aufgeführt sind, anstatt alle Seiten auf der Website zu sehen und diese mit den in der Sitemap aufgeführten Seiten zu vergleichen.
Die Analyse der Sitemap von Labrika hilft, die folgenden Arten von Fehlern zu finden:
- Seiten, die in der Sitemap existieren, aber nicht für die Indexierung zugänglich sind.
- Seiten, die in der Sitemap existieren, aber ein noindex-Tag haben.
- Seiten, die nicht in der Sitemap existieren, aber indexierbar sind.
Bitte beachten: Verschiedene Suchmaschinen verarbeiten Sitemap-Regeln unterschiedlich. Google wird in der Regel nur Seiten indexieren, die über automatisches Crawlen ohne eine Sitemap erreichbar sind. Das heißt, Seiten, die über interne Links innerhalb der festgelegten Crawling-Zeit und Crawling-Tiefe für Ihre Website an diesem Tag erreicht werden können. Sie werden Ihre Sitemap.xml-Datei nicht überprüfen, um festzustellen, welche Links gecrawlt werden sollen, sondern verwenden die Sitemap als Leitfaden, wie oft die in der Sitemap aufgeführten Seiten gecrawlt werden.
Seite existiert in der Sitemap, ist aber nicht für die Indexierung zugänglich
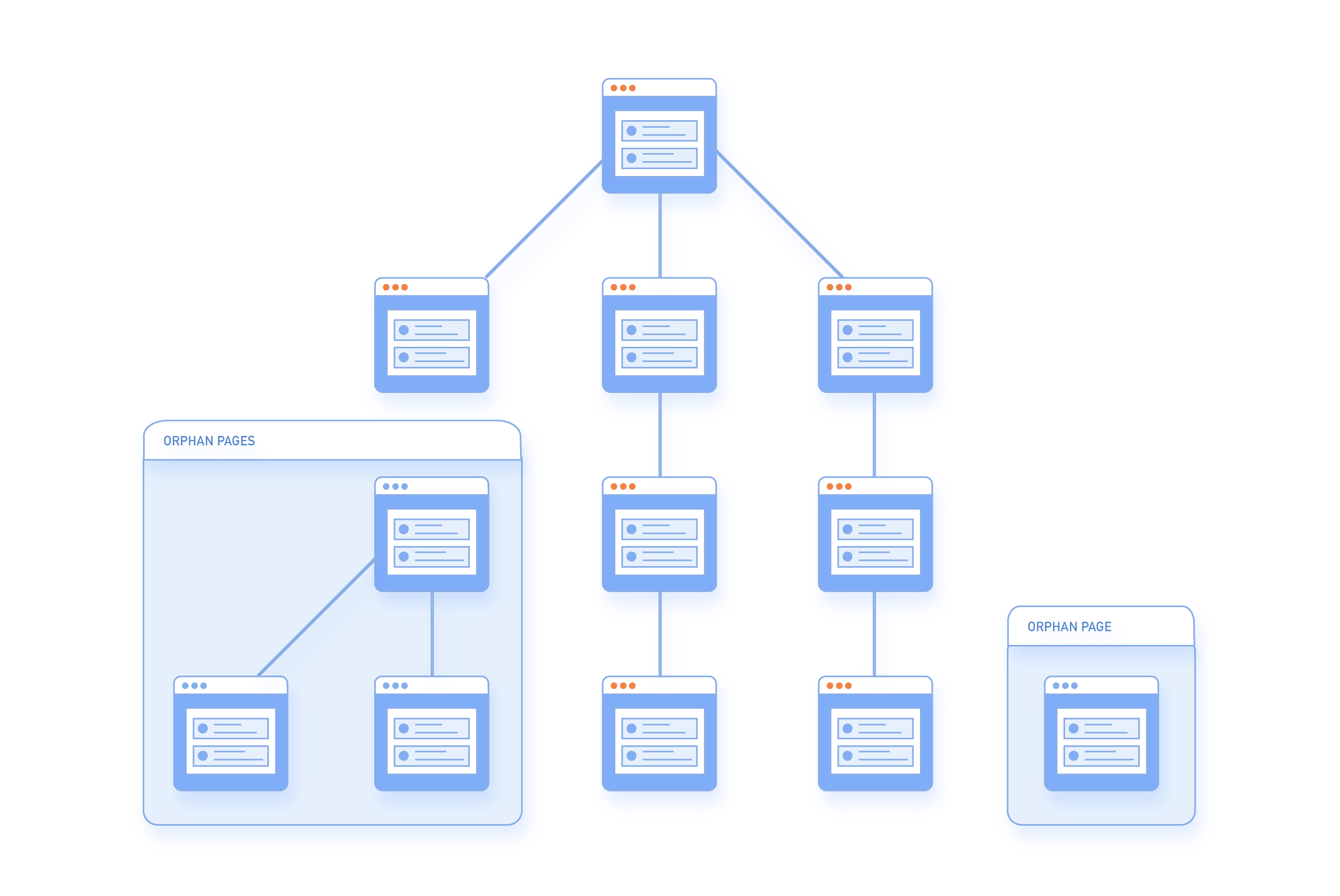
Dieser Bericht hebt hauptsächlich „verwaiste“ Seiten hervor, die im Wesentlichen Seiten sind, die auf Ihrer Website existieren, aber keine eingehenden Links aufweisen und „eigentumslos“ sind.
Im Falle, dass solche Seiten von Suchmaschinen indexiert werden, haben sie wahrscheinlich keinen PageRank und werden nicht gut eingestuft. Es ist gut dokumentiert, dass Google und andere große Suchmaschinen PageRank-Werte (und deren verschiedene Formen) verwenden, um die SEO-Power und den Wert von Seiten zu bestimmen. Vor einigen Jahren ermöglichte Google die Nutzung eines Toolbars, die den PageRank Ihrer Seiten anzeigte, aber leider wurde dies aus der öffentlichen Sphäre entfernt. Natürlich möchten Sie guten PageRank für Ihre verschiedenen Seiten, also wenn eine Ihrer Landingpages in dieser Fehlerkategorie auftaucht (d.h. Ihre Seite ist nicht nur eine verwaiste Seite), sollten Sie sofort die Ursache des Problems finden.
Häufige Gründe, warum Ihre Seite in der Sitemap existiert, aber nicht für die Indexierung zugänglich ist:
- Ein Link von einer Seite mit dem noindex-Tag führt zu dieser Seite oder die Seiten, die zu dieser Seite führen, sind nicht responsiv. Infolgedessen kann der Suchmaschinen-Crawler nicht vorwärts oder rückwärts navigieren und beendet daher die Sitzung.
- Links zu den benötigten Seiten sind blockiert. Zum Beispiel durch das Attribut rel="nofollow". Das heißt, der Crawler sieht den Link zur Seite, kann aber nicht darauf zugreifen, weil dies verboten ist.
- Es gibt keine Links zu dieser Seite und sie ist tatsächlich „verwaist“.
- Die Seite wurde im Website-Editor/CMS gelöscht, aber die HTML-Datei bleibt weiterhin aktiv auf der Seite.
- Die Seite existiert in der Sitemap, ist aber nicht crawlbar, also kann sie nicht indexiert werden.
Diese Art von Fehlern lässt sich am besten beheben, indem Sie Folgendes tun:
- Überprüfen Sie, welche Seiten noindex- und nofollow-Tags haben, und korrigieren Sie dies, oder stellen Sie sicher, dass die Seite korrekt im Hauptmenü hinzugefügt wird, um ein korrektes Crawlen zu ermöglichen. Außerdem sehen wir diese Art von Fehlern häufig bei kommerziellen und informativen Websites, die die Paginierung blockieren.
Wie man das Problem behebt?
Wenn eine Seite in der Sitemap verfügbar ist, aber keine internen Links von einer anderen Seite auf der Website hat, wird sie als verwaiste Seite bezeichnet.
Verwaiste Seiten sind schlecht für SEO, da sie kein Linkgewicht tragen und daher von den Suchmaschinen als unwichtig angesehen werden. Sie wurden auch früher im Black-Hat-SEO verwendet.
Sobald sie in unserem Dashboard identifiziert sind, können Sie:
- Die Seite wieder in Ihr Site-Link-Schema integrieren, wenn die Seite nützlich ist, für Schlüsselwörter rankt oder Backlinks von externen Seiten hat.
- Die Seite mit einer anderen zusammenführen, wenn bereits eine nahezu identische Seite auf der Website verlinkt ist.
- Die Seite vollständig entfernen, wenn sie keinen Nutzen hat. Oder einen 404- oder 410-Code (abgelöschter Inhalt) zurückgeben.
- Für Produktseiten, bei denen der Artikel möglicherweise abgelaufen ist, können Sie auf neue Produkte in derselben Kategorie verlinken, wodurch die Seite zu einer neuen Quelle für Leads wird. (So macht es eBay mit abgelaufenen Auktionseinträgen). Dies hilft, mehr Traffic zu generieren.
Seite existiert in der Sitemap, hat aber ein noindex-Tag
Dies sind Seiten, die mit einem noindex-Tag von der Indexierung ausgeschlossen wurden, aber dennoch irgendwo in der Sitemap existieren.
Menschen setzen noindex-Seiten aus verschiedenen Gründen ein, aber das Vorhandensein von noindex-Seiten in der Sitemap kann zu Leaks vertraulicher Daten führen, führt aber in den meisten Fällen dazu, dass Crawler ihre Zeit und ihr Crawling-Budget verschwenden.
Wie man das Problem behebt?
Dies tritt typischerweise auf, wenn eine Seite durch ein rel="nofollow"-Attribut von der Indexierung blockiert wurde.
Diese Seiten in der Sitemap aufzuführen, ist nicht nützlich, da es Crawling-Budget verbraucht und möglicherweise zu einem Leak vertraulicher Informationen führen könnte. Um dies zu beheben, können Sie die Seite einfach aus Ihrer Sitemap entfernen.
Laden Sie die fehlerfreie sitemap.xml-Datei von Labrika herunter
Für jeden der oben genannten Sitemap-Fehlerberichte bietet Labrika Ihnen die Möglichkeit, eine fehlerfreie und korrigierte Version Ihrer sitemap.xml-Datei herunterzuladen. Dies sollte Ihnen Zeit sparen, um Ihre eigene sitemap.xml-Datei manuell zu korrigieren, und was am wichtigsten ist, eine bessere Nutzung Ihres Crawling-Budgets durch Suchmaschinen ermöglichen.