Robots.txt Validator
Die robots.txt ist eine Textdatei, die Anweisungen (Direktiven) zum Indizieren von Seiten einer Website enthält. Mit dieser Datei können Sie den Suchrobotern mitteilen, welche Seiten oder Abschnitte einer Webseite durchsucht und in den Index (Datenbank der Suchmaschine) aufgenommen werden sollen und welche nicht.
Die robots.txt-Datei befindet sich im Stammverzeichnis der Website und ist unter domain.com/robots.txt verfügbar.
Warum ist robots.txt für SEO notwendig?
Diese Datei gibt den Suchmaschinen wesentliche Anweisungen, die direkt die Effektivität des Rankings einer Website in der Suchmaschine beeinflussen. Die Verwendung von robots.txt kann helfen:
- Das Scannen von doppeltem Inhalt oder für Benutzer nicht nützlichen Seiten (wie interne Suchergebnisse, technische Seiten usw.) durch die Crawler der Suchmaschinen zu verhindern.
- Die Vertraulichkeit von Abschnitten der Website zu wahren (zum Beispiel können Sie systemrelevante Informationen im CMS blockieren);
- Serverüberlastung zu vermeiden;
- Ihr Crawling-Budget effektiv für das Crawlen wertvoller Seiten auszugeben.
Andererseits, wenn die robots.txt Fehler enthält, werden die Suchmaschinen die Website falsch indizieren, und die Suchergebnisse werden falsche Informationen enthalten.
Sie können auch versehentlich das Indizieren nützlicher Seiten verhindern, die für das Ranking Ihrer Website in den Suchmaschinen erforderlich sind.
Inhalt des Berichts „Robots.txt-Fehler“ auf Labrika
Das finden Sie in unserem Bericht über „robots.txt-Fehler“:
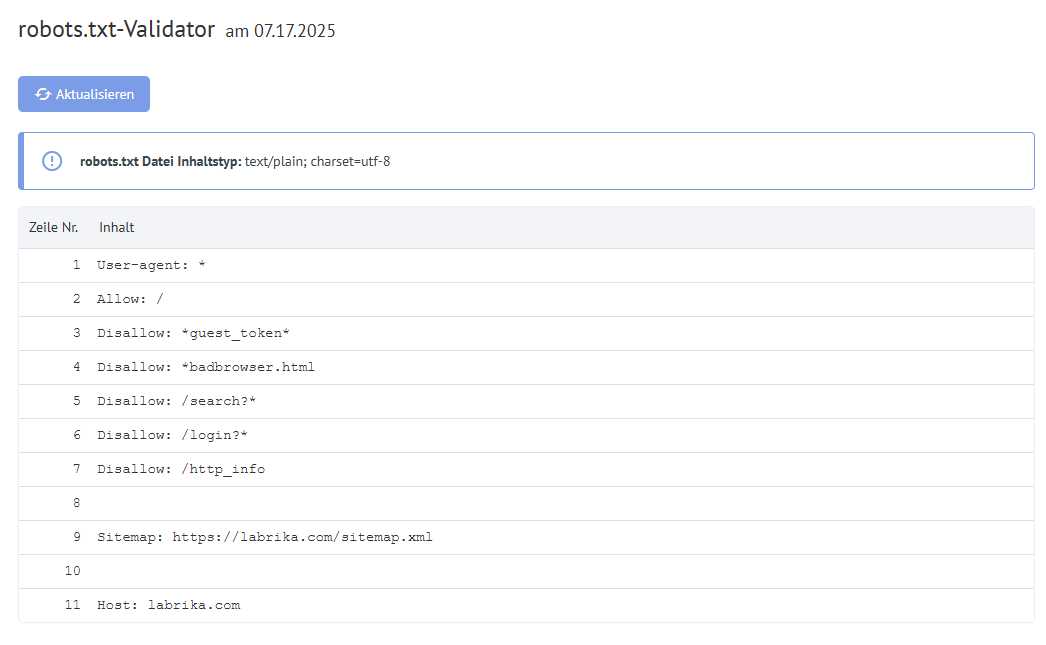
- „Aktualisieren“-Schaltfläche - wenn Sie darauf klicken, werden die Daten zu den Fehlern in der robots.txt-Datei aktualisiert.
- Der Inhalt der robots.txt-Datei.
- Wenn ein Fehler gefunden wird, gibt Labrika die Fehlerbeschreibung an.
Robots.txt-Fehler, die Labrika erkennt
Die Direktive muss durch das Zeichen „:“ von der Regel getrennt sein
Jede gültige Zeile in Ihrer robots.txt-Datei muss den Feldnamen, einen Doppelpunkt und den Wert enthalten. Leerzeichen sind optional, aber für die Lesbarkeit empfohlen. Das Rautezeichen „#“ wird verwendet, um einen Kommentar hinzuzufügen, der vor dem Beginn platziert wird. Der Suchmaschinenroboter ignoriert allen Text nach dem „#“-Symbol bis zum Ende der Zeile.
Standardformat:
<field>:<value><#optional-comment>
Ein Beispiel für einen Fehler:
User-agent Googlebot
Fehlendes „:“ Zeichen.
Korrekter Vorschlag:
User-agent: Googlebot
Leere Direktive und leere Regel
Die Verwendung einer leeren Zeichenfolge in der Benutzer-Agent-Direktive ist nicht erlaubt.
Dies ist die primäre Direktive, die angibt, für welchen Typ von Suchrobotern die weiteren Indizierungsregeln geschrieben sind.
Ein Beispiel für einen Fehler:
User-agent:
Kein Benutzer-Agent angegeben.
Korrekter Vorschlag:
User-agent: der Name des Bots
Zum Beispiel:
User-agent: Googlebot oder User-agent: *
Es muss mindestens eine „Allow“ oder „Disallow“ Direktive enthalten sein
Jede Regel muss mindestens eine „Allow“ oder „Disallow“ Direktive enthalten. „Disallow“ schließt einen Abschnitt oder eine Seite vom Indizieren aus. „Allow“ erlaubt es, Seiten zu indizieren. Zum Beispiel erlaubt es einem Crawler, ein Unterverzeichnis oder eine Seite in einem Verzeichnis zu durchsuchen, das normalerweise von der Verarbeitung ausgeschlossen ist.
Diese Direktiven werden im Format angegeben:
directive: [path]
wobei [path] (der Pfad zur Seite oder zum Abschnitt) optional ist.
Die Robots ignorieren jedoch die Allow- und Disallow-Direktiven, wenn Sie keinen Weg angeben. In diesem Fall können sie den gesamten Inhalt scannen.
Eine leere Direktive Disallow: entspricht der Direktive Allow: /, was bedeutet: „verweigern Sie nichts.“
Ein Beispiel für einen Fehler in der Sitemap-Direktive:
Sitemap:
Der Pfad zur Sitemap ist nicht angegeben.
Korrekter Vorschlag:
Sitemap: https://www.site.com/sitemap.xml
Es gibt keine User-agent-Direktive vor der Regel
Die Regel muss immer nach der User-agent-Direktive kommen. Das Platzieren einer Regel vor dem ersten Benutzernamen bedeutet, dass keine Scanner ihr folgen werden.
Ein Beispiel für einen Fehler:
Disallow: /category
User -agent: Googlebot
Korrekter Vorschlag:
User-agent: Googlebot
Disallow: /category
Verwendung der Form „User -agent: *“
Wenn wir „User -agent: *“ sehen, bedeutet dies, dass die Regel für alle Suchroboter festgelegt ist.
Ein Beispiel:
User-agent: *
Disallow: /
Dies verbietet allen Suchrobotern, die gesamte Website zu indizieren.
Es sollte nur eine User-agent-Direktive für einen Roboter und nur eine „User -agent: *“ Direktive für alle Roboter geben.
Wenn derselbe Benutzeragent in der robots.txt-Datei mehrmals unterschiedliche Regelwerke angegeben hat, wird es für die Suchroboter schwierig sein, zu bestimmen, welche Regeln zu beachten sind. Infolgedessen weiß der Roboter nicht, welcher Regel er folgen soll.
Ein Beispiel für einen Fehler:
User-agent: *
Disallow: /category
User -agent: *
Disallow: /*.pdf.
Korrekter Vorschlag:
User-agent: *
Disallow: /category
Disallow: /*.pdf.
Unbekannte Direktive
Eine Direktive wurde gefunden, die von der Suchmaschine nicht unterstützt wird.
Die Gründe dafür können folgende sein:
- Eine nicht existierende Direktive wurde aufgeführt;
- Es wurden Syntaxfehler gemacht, verbotene Symbole und Tags verwendet;
- Diese Direktive kann von anderen Suchmaschinenrobotern verwendet werden.
Ein Beispiel für einen Fehler:
Disalow: /catalog
Die Direktive „Disalow“ existiert nicht. Es gab einen Schreibfehler im Wort.
Korrekter Vorschlag:
Disallow: /catalog
Die Anzahl der Regeln in der robots.txt-Datei überschreitet das maximal zulässige
Suchroboter verarbeiten die robots.txt-Datei korrekt, wenn ihre Größe 500 KB nicht überschreitet. Die zulässige Anzahl von Regeln in der Datei beträgt 2048. Inhalte über diesem Limit werden ignoriert. Um dies zu vermeiden, verwenden Sie allgemeinere Direktiven, anstatt jede Seite auszuschließen.
Wenn Sie beispielsweise das Scannen von PDF-Dateien blockieren müssen, blockieren Sie nicht jede einzelne Datei. Stattdessen verweigern Sie alle URLs, die .pdf enthalten, mit der Direktive:
Disallow: /*.pdf
Regel überschreitet die zulässige Länge
Die Regel darf nicht länger als 1024 Zeichen sein.
Falsches Regel-Format
Ihre robots.txt-Datei muss im Klartext mit UTF-8 kodiert sein. Suchmaschinen können nicht-UTF-8-Zeichen ignorieren. In diesem Fall funktionieren die Regeln in der robots.txt-Datei nicht.
Damit Suchroboter die Anweisungen in der robots.txt-Datei korrekt verarbeiten können, müssen alle Regeln gemäß dem Robot Exclusion Standard (REP) geschrieben werden, den Google unterstützt und die meisten bekannten Suchmaschinen.
Verwendung nationaler Zeichen
Die Verwendung nationaler Zeichen ist in der robots.txt-Datei verboten. Laut dem standardisierten Domain-Namensystem kann ein Domainname nur aus einer begrenzten Menge von ASCII-Zeichen (Buchstaben des lateinischen Alphabets, Zahlen von 0 bis 9 und einem Bindestrich) bestehen. Wenn die Domain nicht-ASCII-Zeichen (einschließlich nationaler Alphabete) enthält, muss sie in Punycode umgewandelt werden, um ein gültiges Zeichensatz zu erhalten.
Ein Beispiel für einen Fehler:
User-agent: Googlebot
Sitemap: https: //bücher.tld/sitemap.xml
Korrekter Vorschlag:
User-agent: Googlebot
Sitemap: https://xn-bcher-kva.tld/sitemap.xml
Ein ungültiges Zeichen könnte verwendet worden sein
Die Verwendung der Sonderzeichen „*“ und „$“ ist erlaubt. Sie geben Adressmuster an, wenn Sie Direktiven deklarieren, sodass der Benutzer keine lange Liste von endgültigen URLs blockieren muss.
Ein Beispiel:
Disallow: /*.php$
verbietet das Indizieren aller PHP-Dateien.
- Das Sternchen „*“ steht für jede Folge und beliebige Anzahl von Zeichen.
- Das Dollarzeichen „$“ steht für das Ende der Adresse und schränkt die Wirkung des „*“-Zeichens ein.
Wenn „/*.php“ alle Pfade entspricht, die .php enthalten, dann entspricht „/*.php$“ nur den Pfaden, die mit .php enden.
Das „$“-Symbol wird in der Mitte des Wertes geschrieben
Das „$“-Zeichen kann nur einmal und nur am Ende einer Regel verwendet werden. Es zeigt an, dass das Zeichen davor das letzte sein sollte.
Ein Beispiel für einen Fehler:
Allow: /file$html
Korrekter Vorschlag:
Allow: /file.html$
Die Regel beginnt nicht mit einem „/“ oder „*“
Eine Regel kann nur mit den Zeichen „/“ und „*“ beginnen.
Der Pfadwert wird relativ zum Stammverzeichnis der Website angegeben, in dem sich die robots.txt-Datei befindet, und muss mit einem Schrägstrich „/“ beginnen, der das Stammverzeichnis anzeigt.
Ein Beispiel für einen Fehler:
Disallow: products
Der korrekte Vorschlag:
Disallow: /products
oder
Disallow: *products
je nachdem, was Sie vom Indizieren ausschließen möchten.
Ein falsches Sitemap-URL-Format
Die Sitemap dient Suchmaschinen-Crawlern. Sie enthalten Empfehlungen, welche Seiten zuerst gecrawlt werden sollen und in welcher Häufigkeit. Eine Sitemap hilft Robotern, die benötigten Seiten schneller zu indizieren.
Die Sitemap-URL muss enthalten:
- Die vollständige Adresse
- Die Protokollbezeichnung (HTTP:// oder HTTPS://)
- Den Site-Namen
- Den Pfad zur Datei
- Den Dateinamen
Ein Beispiel für einen Fehler:
Sitemap: /sitemap.xml
Korrekter Vorschlag:
Sitemap: https://www.site.ru/sitemap.xml
Falsches Format der „Crawl-delay“-Direktive
Die Crawl-delay-Direktive legt den Mindestzeitraum zwischen dem Ende des Ladens einer Seite und dem Beginn des Ladens der nächsten für den Roboter fest.
Die Crawl-delay-Direktive sollte in Fällen verwendet werden, in denen der Server stark ausgelastet ist und keine Zeit hat, die Anfragen des Crawlers zu verarbeiten. Je größer das festgelegte Intervall, desto weniger Downloads erfolgen während einer Sitzung.
Beim Festlegen eines Intervalls können sowohl Ganzzahlen als auch Bruchzahlen verwendet werden. Ein Punkt wird als Trennzeichen verwendet. Die Maßeinheit ist in Sekunden:
Fehler umfassen:
- Mehrere Crawl-delay-Direktiven;
- Falsches Format der Crawl-delay-Direktive.
Ein Beispiel für einen Fehler:
Crawl-delay: 0,5 second
Korrekter Vorschlag:
Crawl-delay: 0.5
Hinweis: Google unterstützt die Crawl-delay-Direktive nicht. Für einen Google-Bot können Sie die Häufigkeit der Zugriffe im Webmaster-Panel der Search Console festlegen. Die Bots von Bing und Yahoo halten sich jedoch an die Crawl-delay-Direktive.
Die Zeile enthält BOM (Byte Order Mark) - U + FEFF Zeichen
BOM (Byte Order Mark - Byte-Sequenzmarker) ist ein Zeichen der Form U + FEFF, das sich am Anfang des Textes befindet. Dieses Unicode-Zeichen wird verwendet, um die Byte-Sequenz beim Lesen von Informationen zu bestimmen.
Bei der Erstellung und Bearbeitung einer Datei mit Standardprogrammen können Editoren automatisch UTF-8-Kodierung mit einem BOM-Tag zuweisen.
BOM ist ein unsichtbares Zeichen. Es hat keinen grafischen Ausdruck, sodass die meisten Editoren es nicht anzeigen. Aber wenn es kopiert wird, kann dieses Symbol in ein neues Dokument übertragen werden.
Bei der Verwendung eines Byte-Sequenzmarkers in .html-Dateien werden Design-Einstellungen verwirrt, Blöcke verschoben und unleserliche Zeichencodierungen können auftreten. Daher wird empfohlen, das Tag aus Web-Skripten und CSS-Dateien zu entfernen.
Wie entfernt man BOM-Tags?
Das Entfernen des BOM ist ziemlich knifflig. Eine einfache Möglichkeit besteht darin, die Datei in einem Editor zu öffnen, der die Kodierung des Dokuments ändern kann, und sie mit UTF-8-Kodierung ohne BOM erneut zu speichern.
Zum Beispiel können Sie den Notepad++-Editor kostenlos herunterladen. Öffnen Sie dann die Datei mit dem PTO-Tag darin und wählen Sie den Punkt „Kodierung in UTF-8 (ohne BOM)“ im Menü „Kodierungen“ aus.
Wie man robots.txt Validator-Fehler behebt?
Eine robots.txt-Datei sagt den Suchmaschinen-Crawlern, auf welche Seiten sie zugreifen können und auf welche nicht. Typische Fehler und deren Behebung umfassen:
User-Agent: * Disallow: /
Dies bedeutet in der Regel, dass die Live-Seite weiterhin blockiert wird.
- robots.txt befindet sich nicht im Stammverzeichnis. Um dies zu beheben, müssen Sie Ihre Datei einfach in das Stammverzeichnis verschieben.
- Schlechte Verwendung von Platzhaltern wie „*“ (Sternchen) und „$“ (Dollarzeichen). Wenn sie fehlplatziert sind, müssen Sie dieses Zeichen finden und verschieben oder entfernen.
- Zugriff auf Entwicklungsseiten gewähren. Wenn eine Website im Aufbau ist, können Sie die Anweisung „disallow“ verwenden, um das Crawlen zu stoppen. Sobald sie jedoch gestartet ist, müssen diese entfernt werden.
- Wenn Sie sehen:
- Keine Sitemap-URL zu Ihrer robots.txt hinzufügen. Eine Sitemap-URL ermöglicht es den Suchmaschinenbots, einen klareren Überblick über Ihre Website zu erhalten.