Seiten, die von der Indizierung ausgeschlossen sind
Was ist Indizierung?
Indizierung ist der Prozess, bei dem Seiten einer Website analysiert werden (normalerweise von Suchmaschinen durchgeführt) und nach dem Crawlen in die Suchmaschinenindizes aufgenommen werden. Dieser Index (Datenbank) wird dann verwendet, um Suchergebnisse zu erstellen und die Platzierung von Seiten innerhalb der Suchergebnisse zu bestimmen (nachdem Algorithmen die Seiten weiter analysiert haben, basierend auf der Zufriedenheit mit der Suchanfrage und erfolgreicher SEO). Die Indizierung erfolgt durch einen Crawler/Suchmaschinen-Roboter.
Warum benötigen wir die Möglichkeit, Informationen von Suchmaschinenindizes auszuschließen?
Als Faustregel gilt, dass Informationen, die nicht in den Suchergebnissen angezeigt werden sollen, durch das „noindex“-Tag oder durch das Blockieren des Crawlings bestimmter Abschnitte/Seiten der Website in der robots.txt-Datei ausgeschlossen werden können. Seiten, die normalerweise von Suchmaschinen blockiert werden, sind technischer, proprietärer und vertraulicher Natur und gelten als ungeeignet für die Platzierung in den Suchergebnissen.
Beispiele hierfür auf einer kommerziellen Website können Links zu Benutzerkonten, Warenkörben, Produktvergleichen, doppelten Seiten, Suchergebnissen innerhalb der Website usw. sein!
Diese Seiten sind für Kunden wertvoll und für die Funktionalität der Website unerlässlich, sind jedoch für Suchmaschinenindizes nicht nützlich.
Methoden zum Blockieren von Seiten von der Indizierung durch Suchmaschinen
Es gibt viele Möglichkeiten, die Indizierung von Seiten zu verhindern:
1. Verwendung einer robots.txt-Datei.
Die robots.txt-Datei ist eine Textdatei, die Suchmaschinen mitteilt, welche Seiten sie indizieren können und welche nicht.
Um eine Seite in robots.txt von der Indizierung auszuschließen, müssen Sie die Disallow-Direktive verwenden.
# Der Inhalt der robots.txt-Datei,
# die im Stammverzeichnis der Website sein muss
# ermöglicht die Indizierung von Seiten und Dateien, die mit '/catalog' beginnen
Allow: /catalog
# blockiert die Indizierung von Seiten und Dateien, die mit '/cart' beginnen
Disallow: /cart
2. Verwendung des -Robots-Tags mit dem noindex-Attribut.
Um eine Seite mit diesem Attribut zu blockieren, müssen Sie die folgenden Zeilen in den <head>-Bereich der Seite einfügen:
<meta name="robots" content="noindex">
3. Nofollow-Links, damit die Seite, auf die sie verlinken, nicht indiziert wird.
Es gibt zwei Möglichkeiten, dies zu tun:
- Blockieren des Crawlers, der einem Link auf Linkbasis folgt:
<a href="/page" rel="nofollow"> Linktext </a> - Blockieren des Crawlers, der einem Link auf der Seite folgt, indem der Seite selbst das nofollow-Attribut gegeben wird:
<meta name="robots" content="nofollow" />
4. Blockieren Sie die Seite von einem bestimmten Suchmaschinen-Crawler im Header der HTML-Seite.
Sie können diese Zeile im <head>-Bereich der Seite platzieren; dies blockiert die Seite von der Indizierung durch Google:
<meta name="googlebot" content="noindex">
5. Kanonische Seite.
Das rel=canonical-Attribut wird verwendet, um der Suchmaschine anzuzeigen, dass die Seite eine kanonische Seite ist (die autoritativste). Dies zeigt dem Crawler, dass dies die bevorzugte Seite zur Indizierung ist.
<link rel="canonical" href="https://example.com/catalog/shirt" />
6. Verwendung des "X-Robots-Tag" HTTP-Anforderungsheaders für eine bestimmte URL:
HTTP / 1.1 200 OK
X-Robots-Tag: google: noindex
Wie finde ich Seiten, die von der Indizierung auf meiner Website ausgeschlossen sind?
Sie können diese Informationen im Abschnitt "SEO-Audit" - "Seiten, die von der Indizierung ausgeschlossen sind" Ihres Labrika-Dashboards einsehen.
Labrikas Bericht „Seiten, die von der Indizierung ausgeschlossen sind“
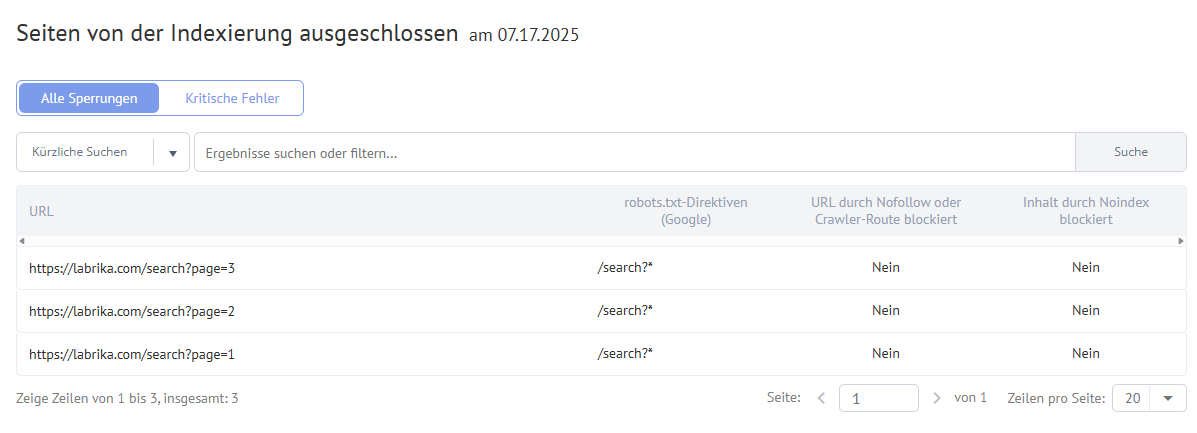
- Die URL von Seiten, die derzeit von der Indizierung ausgeschlossen sind.
- Die Direktive in robots.txt, die die Indizierung für diese Seite blockiert.
- Ob diese Seite über das nofollow-Attribut blockiert wurde.
Wie stoppe ich eine Seite von der Indizierung, die in diesem Bericht aufgeführt ist?
In vielen modernen Content-Management-Systemen (CMS) können Sie die robots.txt-Datei, rel=canonical, das "robots"-Meta-Tag, "noindex" und "nofollow"-Attribute ändern. Um eine Seite, die in diesem Bericht enthalten ist, wieder indizierbar zu machen, müssen Sie nur das Attribut/Tag entfernen, das die Seite von der Indizierung ausschließt.